
“Beliefs are hypotheses to be tested, not treasures to be protected.” – Philip E. Tetlock and Dan Gardner
Thinking, Fast and Slow is one of my favorite books. In it, Daniel Kahneman details how the human mind works in two modes: one fast and effortless, the other slow and laborious. You engage the slow system to split the check among three friends. The fast system works automatically, filling in blanks and recognizing patterns. It allows us operate smoothly on partial information. However, that quick judgement system can also lead us into dangerous biases and overconfidence.
In Superforecasting: The Art and Science of Prediction, Tetlock and Gardner apply the principles of behavioral economics to the practice of forecasting. Tetlock is the researcher whose previous studies led him to conclude that most expert prognosticators predicted future events no more accurately than dart-throwing chimps.
Tetlock led a major prediction effectiveness study called The Good Judgement Project (GJP). Tetlock and his co-researchers enlisted several thousand volunteers as contestants in a prediction competition. To be statistically meaningful, contestants had to make hundreds of predictions. They were of the sort… Will Scotland vote to secede from the UK? Will the Swiss examination of Yasser Arafat’s exhumed bones find traces of polonium?
They established a system by which competitors were scored based on a combination of correctness and confidence level. They identified the top 2% as superforecasters. These people consistently predict events with much higher accuracy than everyone else.
You might expect that intelligence is the primary factor that sets the superforecasters apart from the rest, but while they were of above-average intelligence (top 20% of the population), it was the superforcaster’s ability to stay objective, counteract their own biases, and question their own beliefs that make them different and so effective. In large part, they were better at avoiding the biases identified by Kahneman.
From the book, here is a summary of the traits of the superforecasters:
In philosophic outlook, they tend to be:
CAUTIOUS: Nothing is certain
HUMBLE: Reality is infinitely complex
NONDETERMINISTIC: What happens is not meant to be and does not have to happenIn their abilities and thinking styles, they tend to be:
ACTIVELY OPEN-MINDED: Beliefs are hypotheses to be tested, not treasures to be protected
INTELLIGENT AND KNOWLEDGEABLE, WITH A “NEED FOR COGNITION”: Intellectually curious, enjoy puzzles and mental challenges
REFLECTIVE: Introspective and self-critical
NUMERATE: Comfortable with numbersIn their methods of forecasting they tend to be:
PRAGMATIC: Not wedded to any idea or agenda
ANALYTICAL: Capable of stepping back from the tip-of-your-nose perspective and considering other views
DRAGONFLY-EYED: Value diverse views and synthesize them into their own
PROBABILISTIC: Judge using many grades of maybe
THOUGHTFUL UPDATERS: When facts change, they change their minds
GOOD INTUITIVE PSYCHOLOGISTS: Aware of the value of checking thinking for cognitive and emotional biasesIn their work ethic, they tend to have:
A GROWTH MINDSET: Believe it’s possible to get better
GRIT: Determined to keep at it however long it takes
To learn what each of these traits mean and how superforecasters manifest them to make significantly better predictions than their peers, check out the book. It’s like Thinking Fast and Slow applied to prediction with a heavy dose of The Black Swan, The Wisdom of Crowds, and Mindset. It was a great read/listen, and I highly recommend it!

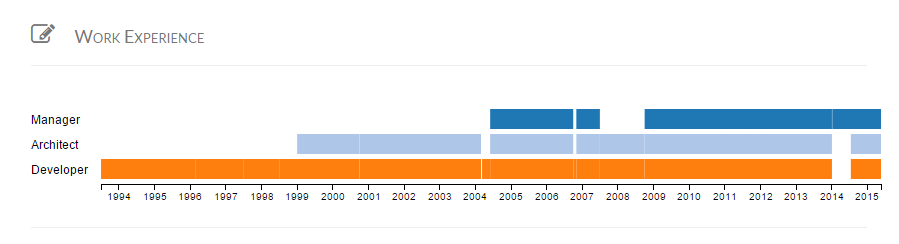
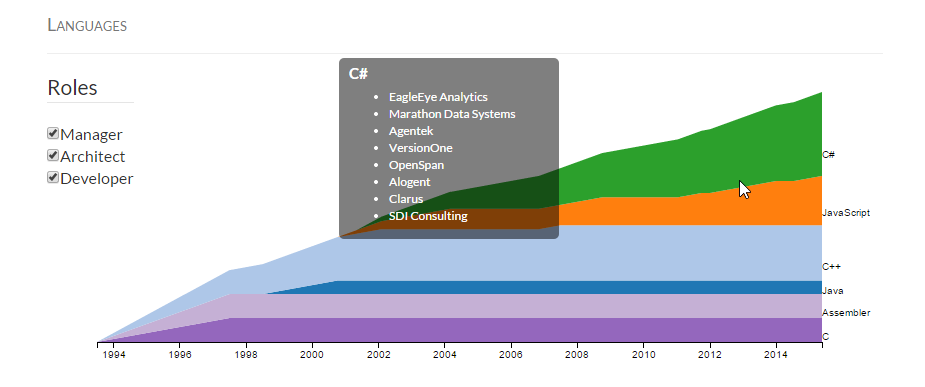




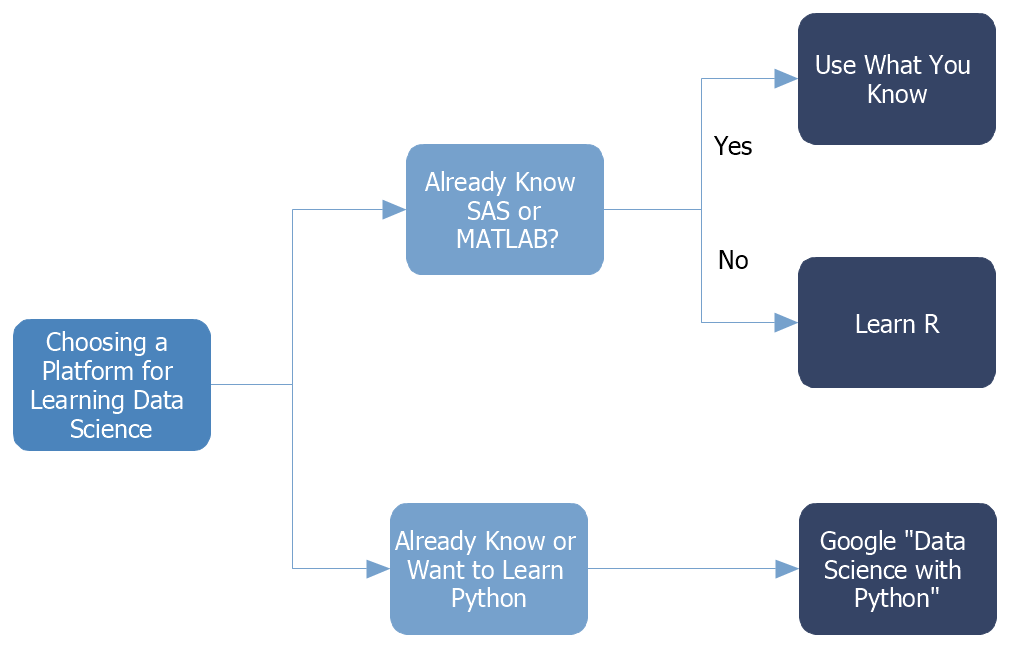
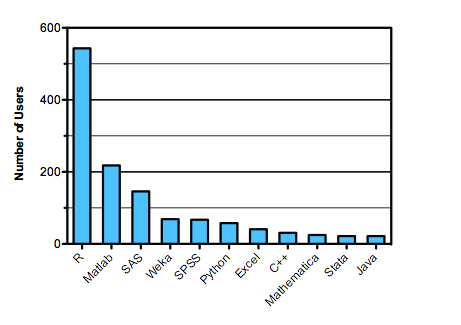

 I enjoyed a moment today that would warm the heart of any geeky dad. Sitting in church this morning, the pastor told the story of his college days when he read
I enjoyed a moment today that would warm the heart of any geeky dad. Sitting in church this morning, the pastor told the story of his college days when he read